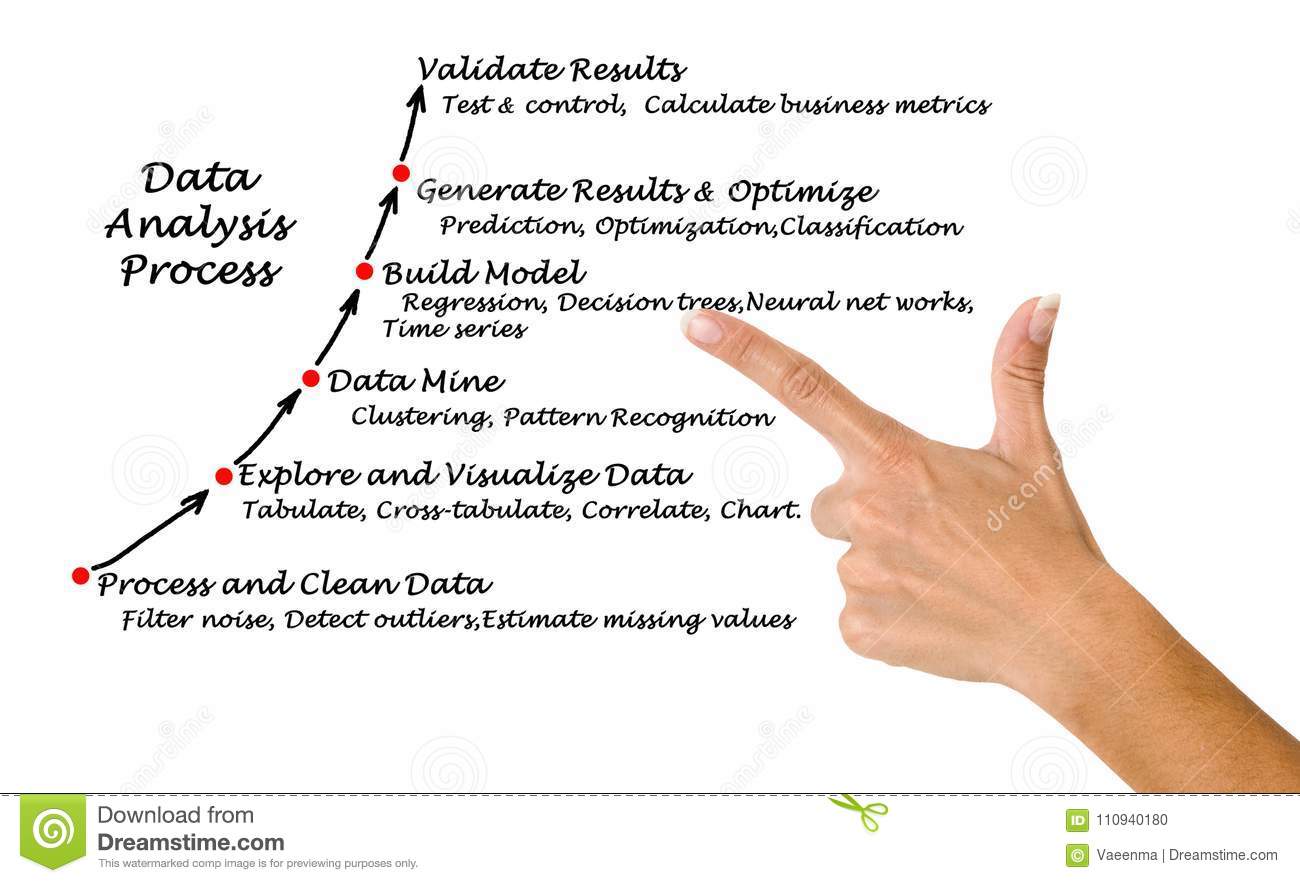
Aqui te presentamos los diferentes modelos que podrás utilizar para clasificar diferentes objetos, servicios, productos o algún otro item que estes considerando analizar. La mayoria de los modelos de clasificación se pueden encontrar en librerias hechas en python o programas especializados en mineria de datos tales como rapidminer, tableau, srss, BI de microsoft, informatica entre otros.
- Regresión logística.- Una función logística usa probabilidades para describir el posible resultado de una sola prueba. Solo funciona cuando la variable predicha es binaria. Supone que los predictores son independientes y no tienen valores perdidos.
- Naive Bayes.-Objetos discriminatorios. Un clasificador Naive Bayes es un modelo probabilístico de aprendizaje automático que se utiliza para la tarea de clasificación. Asume independencia entre el par de características. El quid del clasificador se basa en el teorema de Bayes. Ejemplos: Filtrado de spam y Clasificación de documentos
- Clasificador de vecinos.-K es un número que puede elegir y luego los vecinos son los puntos de datos de datos conocidos. Se seleccionan las N observaciones más cercanas de un espacio de entrada X, se miden la distancia euclidiana y se promedian. Este modelo puede adaptarse y no se basa en supuestos estrictos sobre los datos subyacentes. La dimensionalidad de la maldición ocurre cuando este método intenta producir funciones que varían localmente en pequeños vecindarios isotrópicos. Por tanto, se producen problemas de grandes dimensiones.
- Árbol de decisión.- Este método utiliza los datos y sus clases para crear una secuencia de reglas para clasificar los datos. Los árboles de decisión pueden no generalizar bien los datos y los árboles pueden ser inestables.
- Bosque aleatorio: es un modelo de clasificación que se basa en los fundamentos de los árboles de decisión. Utiliza ensacado (recolectando datos al azar de un conjunto de datos con reemplazo) y presenta aleatoriedad para fomentar bosques de árboles no correlacionados (esto hace que la predicción sea más precisa que los modelos de árboles de decisión individuales)
- Redes neuronales.- Estos modelos son los más utilizados en problemas complejos que normalmente involucran la resolución de ecuaciones diferenciales totales o parciales. Al no basarse en procedimiento definido este modelo es considerado como una caja negra donde se ingresan datos para su modelación y posterior clasificación de datos.
- Árbol de decisión de aumento de gradiente.- Se diferencia de adaboost en la profundidad en la que se calcula la media.
- Clasificador SGD (descenso de gradiente estocástico) .- Se utiliza con clasificación de texto y procesamiento de lenguaje natural. Buenos resultados con problemas de aprendizaje automático escasos y a gran escala. Las desventajas son sensibles a la característica de escalado y requieren una serie de hiperparámetros.
- SVM (máquina de vectores de soporte) .- El clasificador separa los puntos de datos utilizando un hiperplano con la mayor cantidad de margen. SVM se puede utilizar para clasificación (distinguir entre varios grupos o clases) y regresión (obtener un modelo matemático para predecir algo). Se pueden aplicar a problemas lineales y no lineales. Es eficaz en espacios de gran dimensión y es eficiente en la memoria porque utiliza un subconjunto de puntos de entrenamiento en la función de decisión. Este es un modelo de clasificación no lineal. Ejemplos de aplicación SVM: Reconocimiento de caracteres escritos a mano, Reconocimiento de imágenes, ◦ Categorización de texto e hipetexto