La regresión logística se utiliza para encontrar las probabilidades o la razón de eventos en los que ocurre un evento específico en relación con otros eventos. Este método de aprendizaje automático también se utiliza en problemas de regresión que requieren identificar la probabilidad de ocurrencia de una variable dependiente específica. Tiene la ventaja de encontrar la relación entre una variable dependiente y una o más variables independientes aplicando el log (probabilidades). y su probabilidad de ocurrencia en un problema específico. La salida del modelo logístico tiene valores limitados disponibles.
Los científicos de datos que requieren clasificar una variable dependiente asumen que los datos de la muestra están distribuidos en bernoulli para predecir la probabilidad de que ocurra un problema binario (pasa / no pasa, sí / no).
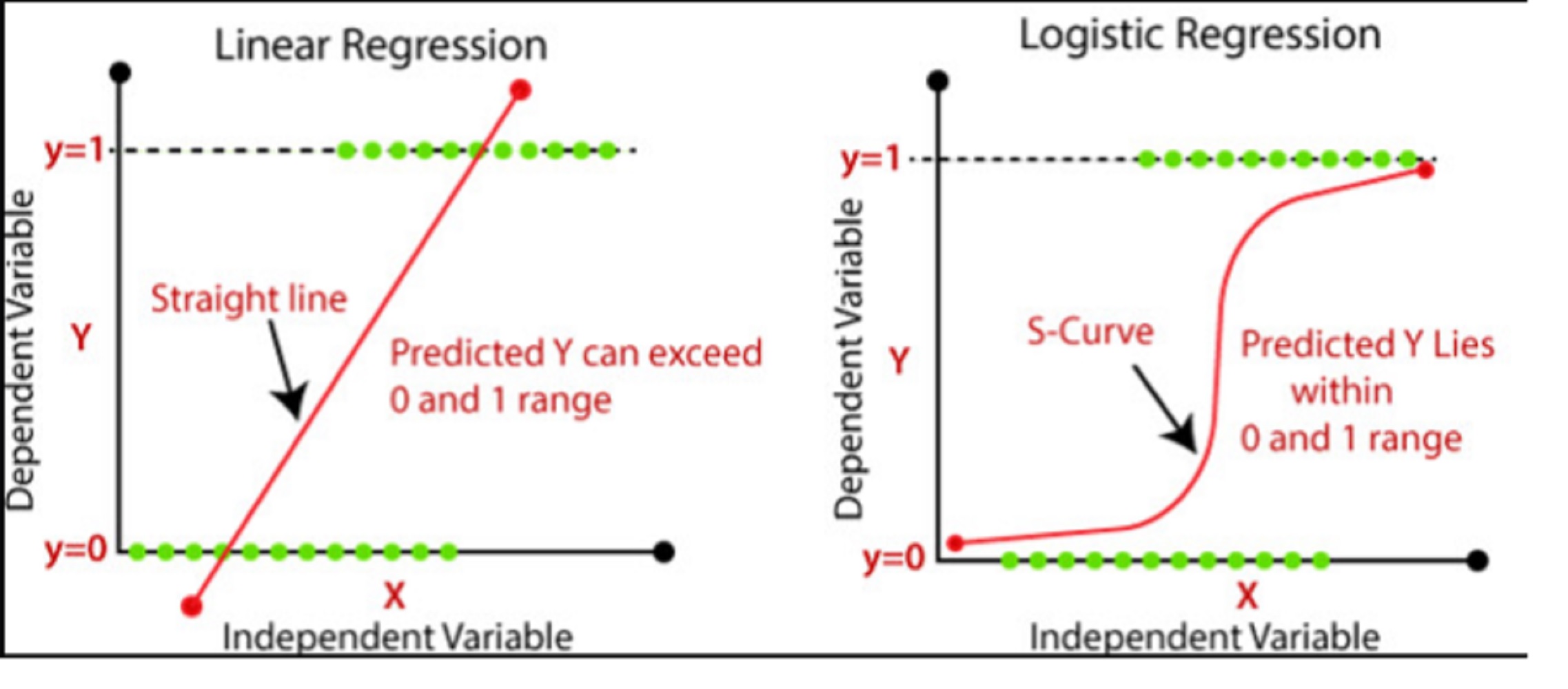
Cómo se Calculan los Coeficientes en una Regresión Lineal y una Regresión Logística.
La regresión logística es similar a la regresión lineal porque ambos métodos de cálculo usan una línea para establecer la relación entre las variables dependientes e independientes; sin embargo, la diferencia se basa en que los coeficientes de la regresión logística se calculan en función del logg (probabilidades) de sus variables.
¿Cómo Encontrar el Mejor Modelo con la Regresión Logística?
Otra diferencia radica en la forma en que los datos se ajustan al modelo de regresión logística. Sus coeficientes y línea de regresión se calculan e iteran para converger hacia la máxima probabilidad. La probabilidad de un modelo de regresión logística multivariado se obtiene como el producto de las probabilidades de todas las variables o características independientes de nuestro modelo. La adición del logaritmo (impar) de cada una de las características o variables independientes también lo lleva a obtener la probabilidad como se indica a continuación:
Probabilidad de los datos dados en el garabato = log (Po1) + log (Po2) + log (Po3) + log (Po4) + log (Po5) + log (Po6)
Probabilidad de los datos dados en el garabato = Po1xPo2xPo3xPo4xPo5xPo6
Por otro lado, los datos se ajustan al modelo de regresión lineal hasta que los mínimos cuadrados convergen hacia un valor mínimo.
¿Cómo Calcular la Regresión Logística la Probabilidad de que Ocurra un Evento?
Se encuentra que los parámetros se ajustan a un modelo con los datos y luego se encuentra la probabilidad a partir de la ecuación o modelo con los valores conocidos de las variables independientes.
En general, los logaritmos (probabilidades) se convierten en probabilidades siguiendo esta ecuación por característica contenida en nuestro modelo:
p = exp (log (probabilidades)) / (1 + exp (log (probabilidades))
Estas probabilidades forman un garabato cuando se trazan en un gráfico que contiene todas las variables o características independientes en nuestro modelo.
A continuación, se muestra un ejemplo en el que puede verificar cómo se usa la regresión logística para encontrar la probabilidad de aprobar un examen en función del número de horas estudiadas. La regresión logística podría calcularse a partir de datos y representarse con un modelo como este.
Probabilidad de aprobar = 1 / (1 + exp (- (1.5046 * horas-4.0777))
La ecuación que representa la relación entre variables dependientes e independientes podría tener esta forma:
p = 1 / (1 + b- (Bo + B1x1 + B2x2))
dónde:
p = probabilidad de aprobar un examen
b = base logarítmica generalmente elegida como exponencial (exp) o base 2 o base 10 (log)
B1, B2 = parámetros
Bo = intersección con el eje
x1, x2 = predictores
Se podría encontrar una solución al predecir la probabilidad de que una persona apruebe con una calificación superior a 3,1.