-
Tipos de Modelos de Datos

Aqui te presentamos los diferentes tipos de modelos de datos que puedes implementar en algoritmos de aprendizaje computarizados. Estos modelos los describimos de manera breve para que conozcan de manera general las opciones que existen en la ciencia de datos. Paramétrico: haga suposiciones para obtener un modelo de una figura o forma específica y parámetros…
-
Cómo Realizar la Validación Cruzada y Cruce Seccional de Datos
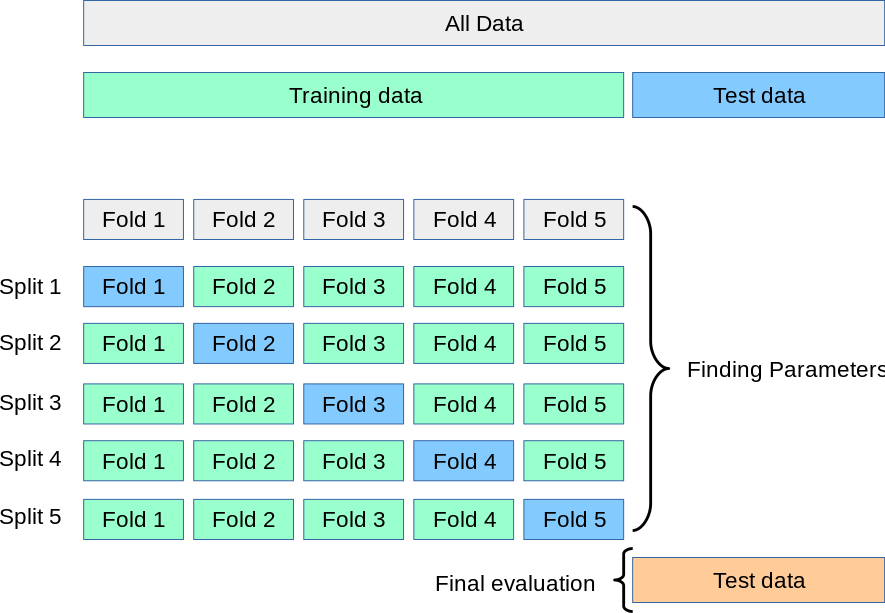
Validación cruzada La validación cruzada es el proceso de dividir un conjunto de datos en un conjunto de entrenamiento y un conjunto de pruebas para mejorar la aptitud y el rendimiento del modelo. Se basa en el principio de que los datos entrenados deben ajustarse lo suficientemente bien como para ser probados con datos desconocidos.…
-
¿Cuál es la diferencia entre MSE y RMSE?

MSE es la medida de calidad del estimador y se representa como la varianza. Incorpora el error de varianza, que es la extensión generalizada de las estimaciones de una muestra de datos a otra y el sesgo, que es qué tan lejos está del verdadero valor. MSE = sesgo ^ 2 + varianza. RMSE es…
-
Problema de regresiónes – Regresión Lineal y Regresión Logaritmica – Análisis Detallado

Modelos de aprendizaje automático utilizados para resolver la regresión: admite regresión vectorial, regresión lineal, árbol de decisión, vecinos más cercanos, árbol de regresión y bosque aleatorio (el promedio de resultados se utiliza para obtener el valor regresado), descenso de gradiente estocástico. Regresión lineal Hay varios valores en la salida del modelo. Por ejemplo, puede tomar…
-
Modelado de Datos: Conceptos y Temas en la Modelación de Datos – Carreras Universitarias

El modelado es la tarea que incorpora información en una herramienta para predecir o pronosticar eventos. Esta herramienta podría ser una función que represente la relación entre Y y X (X1, X2, X3, etc.) y que contenga un error aleatorio (e). Este error puede ser irreducible o reducible para que se obtenga un modelo estimado…